為替情報の幾何的特徴を用いた売買アルゴリズムの検討
※スライド埋め込みあり
はじめに
- 近年、AIを用いて金融市場の売買タイミングを判定しようという試みが活発に行われている。
- 例えば石原[4]は多層ニューラルネットワークと遺伝的アルゴリズムを用いたトレーディング手法によって、TOPIXを上回る運用成績を達成したことを報告している。
- また、今村ら[5]は、金融実務に置いて伝統的に用いられているペアトレードと呼ばれる手法と、LSTM(Long Short Term Memory)を組み合わせることで、良好な結果を得ている。
- 今回の研究では、為替取引(ドル円)に対して機械学習を用いたアプローチによってリターンを上げることを目標にする。
1. ユーザーのニーズと相場環境
我々と取引がある機関投資家の皆様をはじめ、「FX取引で利益をあげたい」、あるいは「大損を避けたい」というニーズは普遍的に存在する しかし、現在の為替市場では様々な条件(金利、金融システムの安定度、政治情勢、モメンタム etc)が複雑に絡み合っているため、既知分布を仮定してもうまく相場変動を説明できない場合がある。
→ 従来の手法がデータに対して分布を仮定することで情報を取りこぼしてきたという梅田ら[6]の指摘を踏まえ、今回は特別な仮定をおかずに「形」を把握することでデータの構造を捉えようとした PointNet++が有効と思われる。
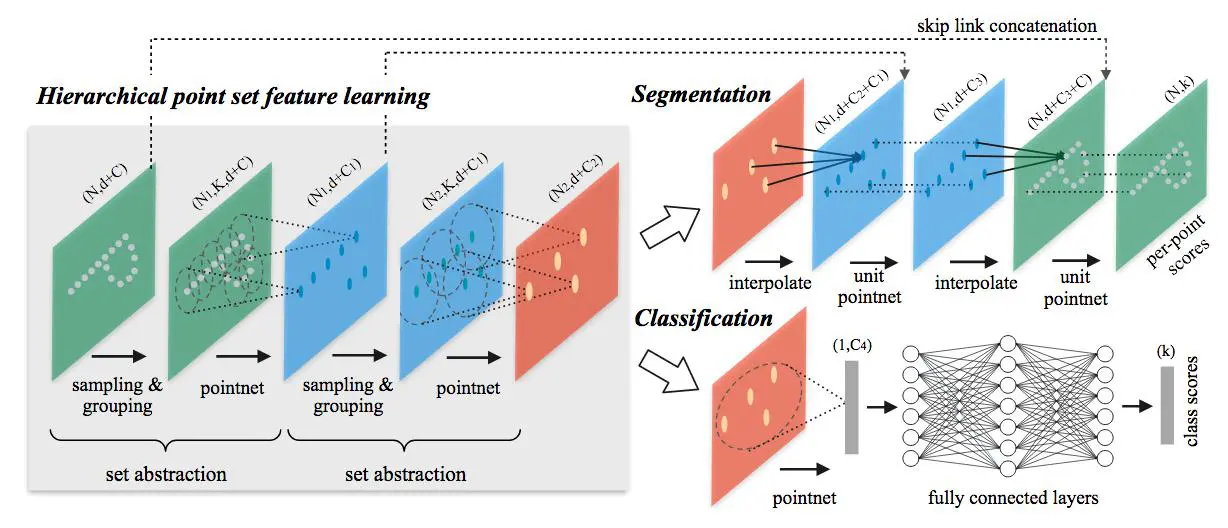
2. PointNet++ とは(成立過程)
- C.R.Qi et al [2]は、物体を描画した点群を三次元ボクセルや画像に変換することなく、直接処理することができるアーキテクチャを提案した
→ PointNet - さらに、C.R.Qi et al [3]は PointNet のネットワークに階層的な構造を導入することで、インプット情報の局所的な構造を捉える精度を向上させた
→ PointNet++
3. 売買戦略
- 学習後のPointNet++を用いて、ドル円がn pips以上上昇すると予測された場合にドル買いを、n pips以上下落すると予測された場合にドル売りを行いそのパフォーマンスを検証する。(n=1,5)
- 結果の評価は、学習に用いていない未知のデータに対するシミュレーションにおいて、通算の利益(あるいは損失)をみることで行う
4. データ準備
- FXDDから2005年1月から2018年7月までのドル円の為替データ(1分足)を入手
- このデータを5分足に変換した後、全体の4分の3を学習用データに、残りの4分の1をテスト用データに割り振った
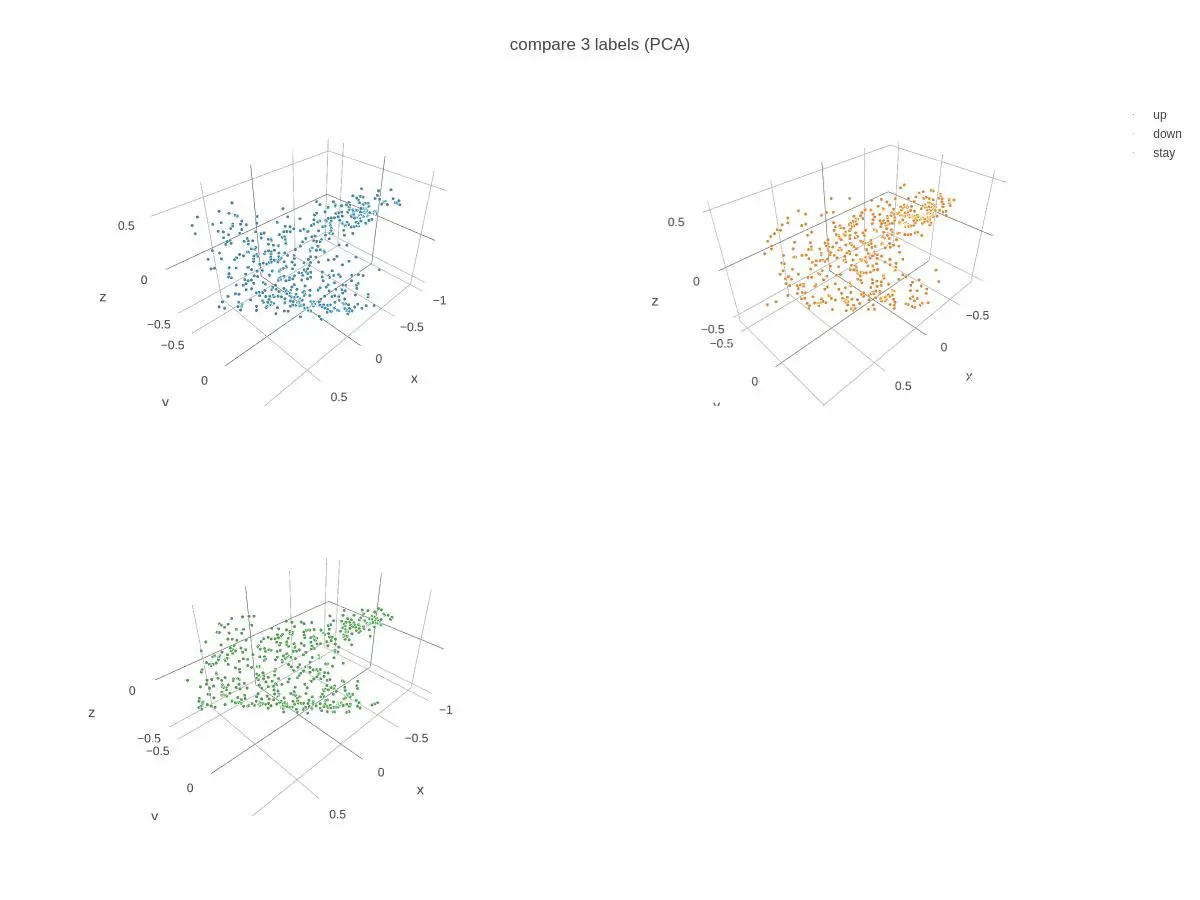
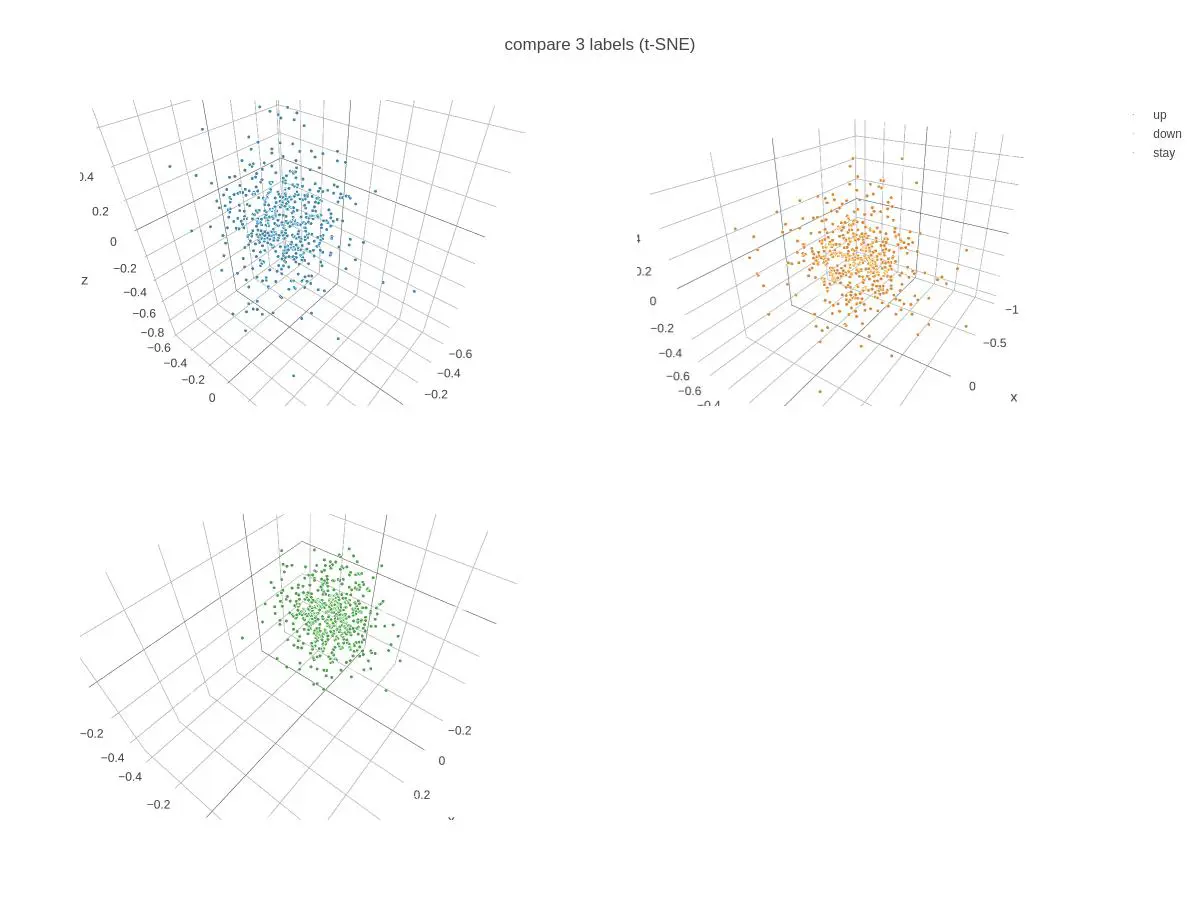
- 各時点で、金融実務でよく用いられる15指標(次スライド参照)を算出した。 ここから、主成分分析(PCA)とt-SNEを用いてデータの次元を15から3に削減し、これを学習器の入力とした。
参考(https://secure.fxdd.com/us/jp/forex-resources/forex-trading-tools/metatrader-1-minute-data/)
5. 今回用いた15指標一覧
・Absolute Price Oscillator ・Aroon Down ・Aroon Up ・Average True Range ・Chande Momentum Oscillator ・Rate Of Change ・Minus Directional Movement ・Midpoint ・Plus Directional Movement ・Relative Strength Index ・Slow %D ・Slow %K ・Simple Moving Average ・Ultimate Oscillator ・William’s %R
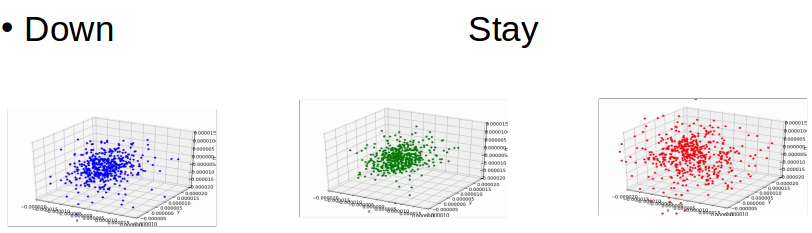
6. 主成分分析(PCA)による三次元散布図
7. t−SNEによる三次元散布図
8. 学習方法
- PCAおよびt-SNEを用いて、インプット情報を三次元データとする
- 正解ラベルは5分後の価格変動に応じて行う(表1)
- 連続する512時点分の三次元データを間隔256で移動させて順次入力
→パラメーター最適化

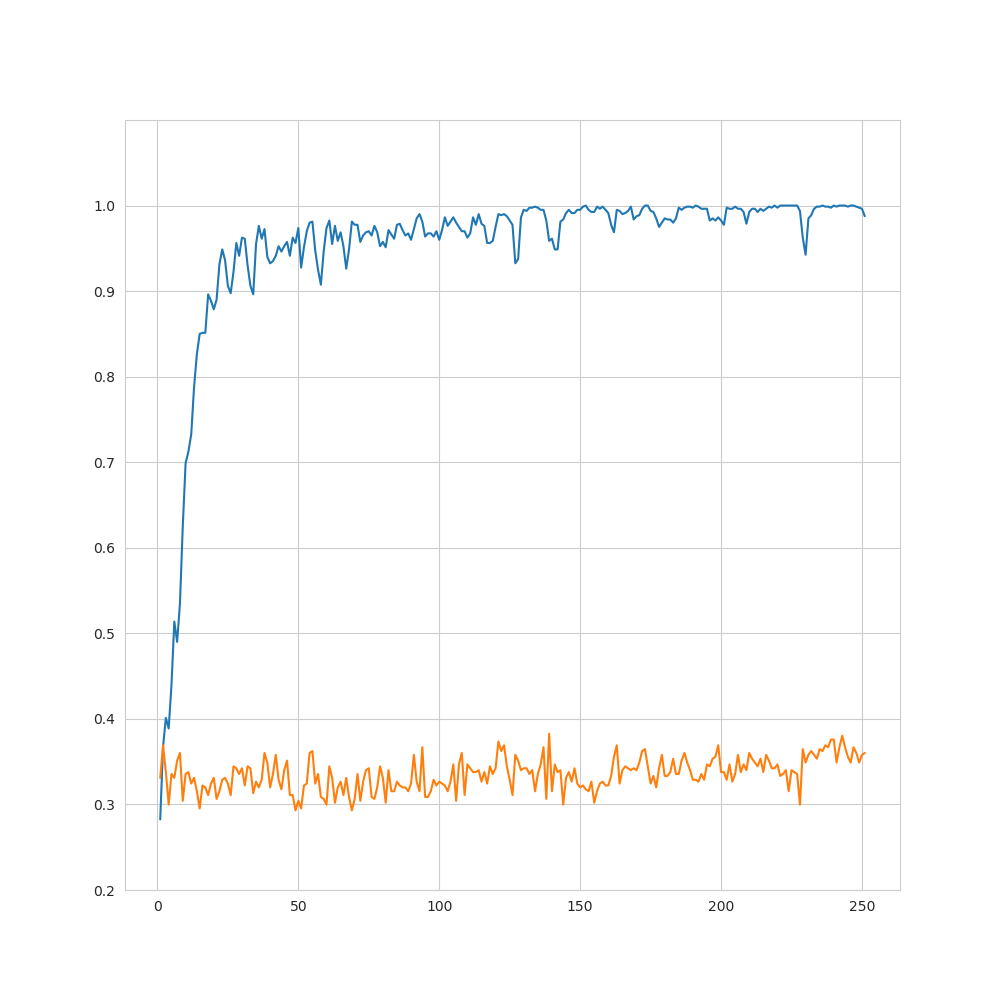
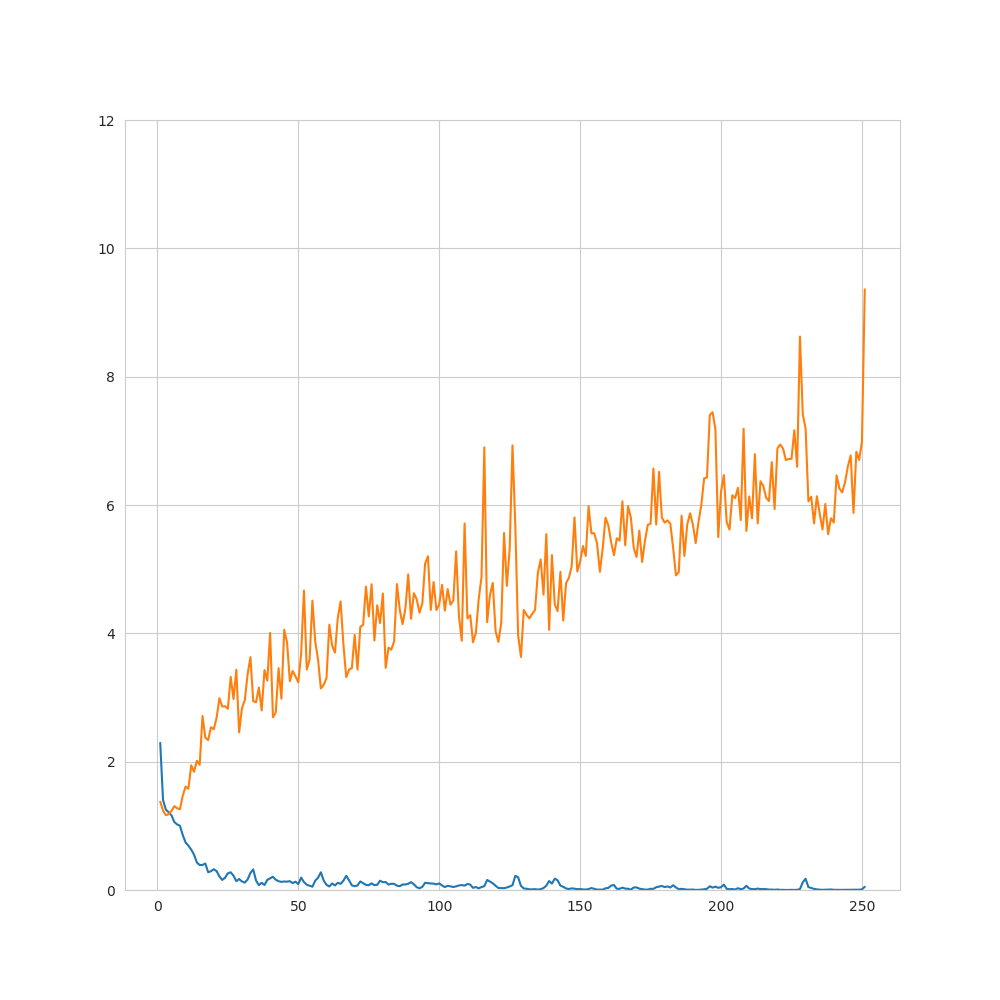
9. 結果(損失関数および予測精度–1pips/PCA)
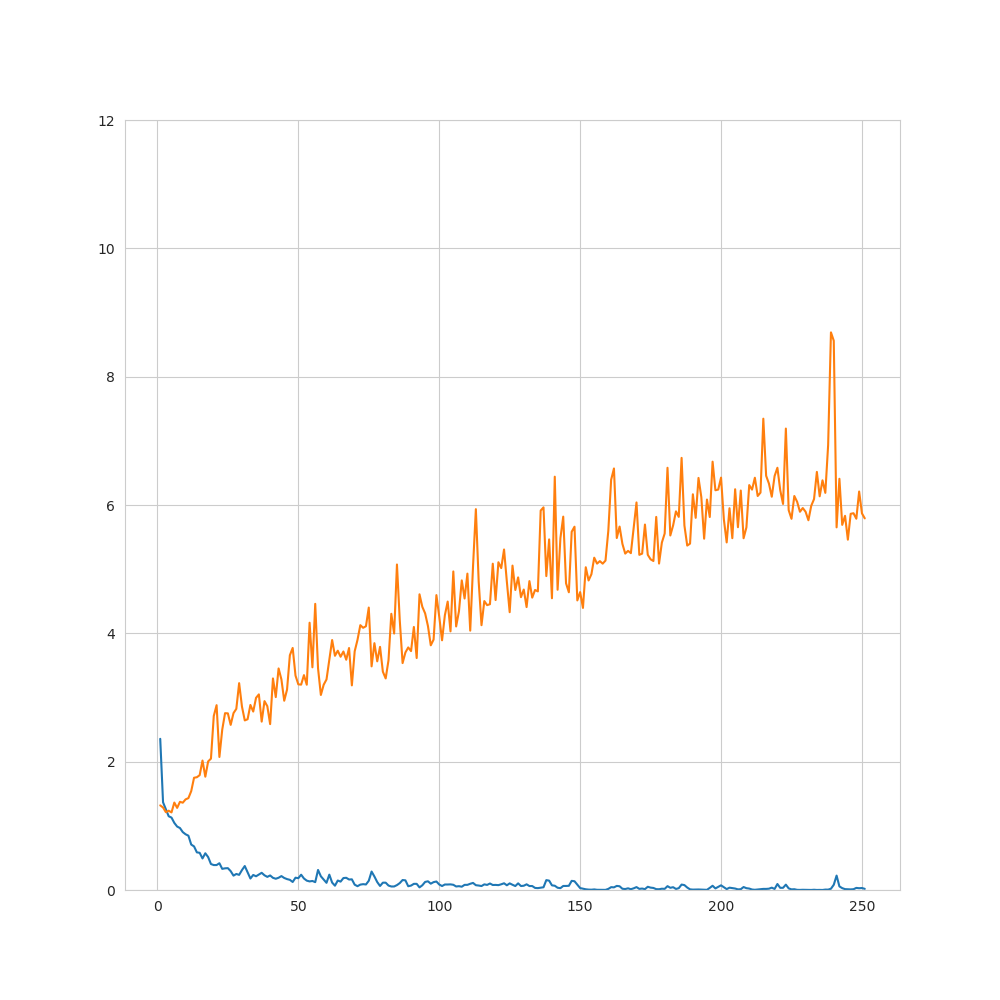
9. 結果(損失関数および予測精度–1pips/t-SNE)
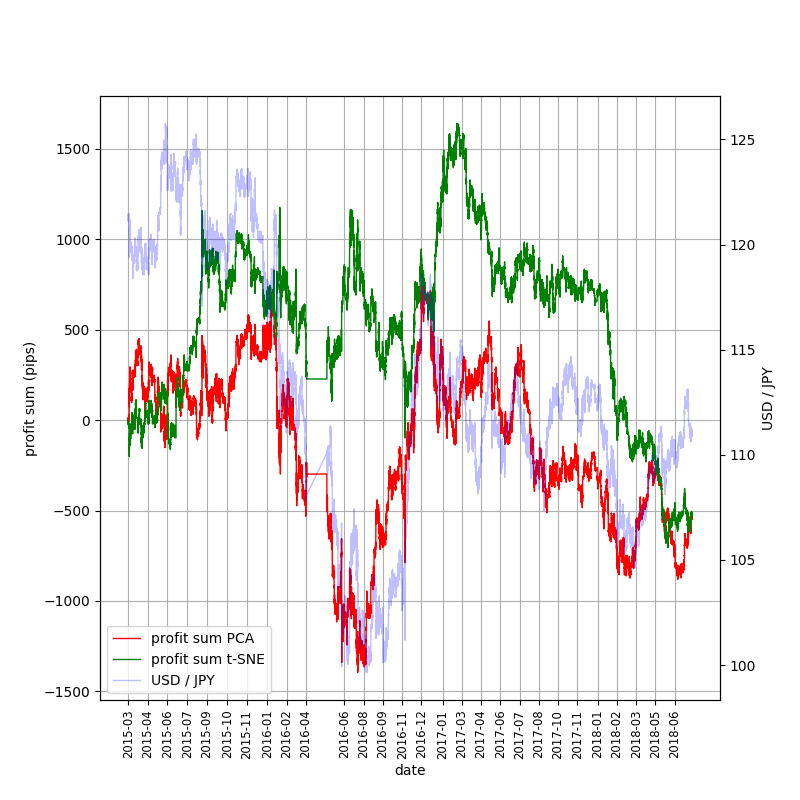
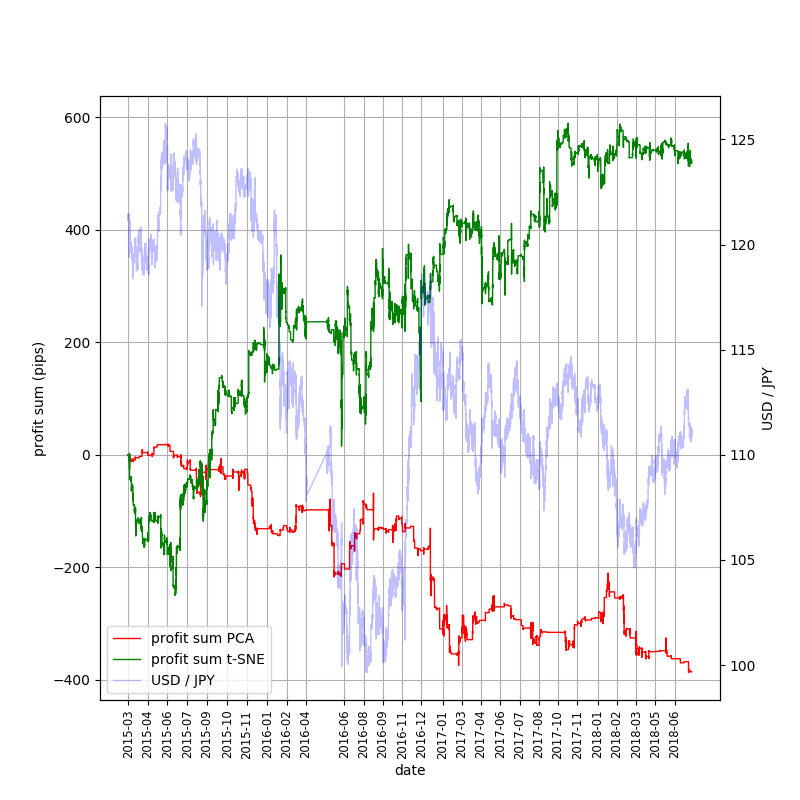
9. 結果(売買シミュレーション–1pips)
9. 結果(売買シミュレーション–5pips)
9. 学習データの表現について
人間にわかる特徴はなかった。
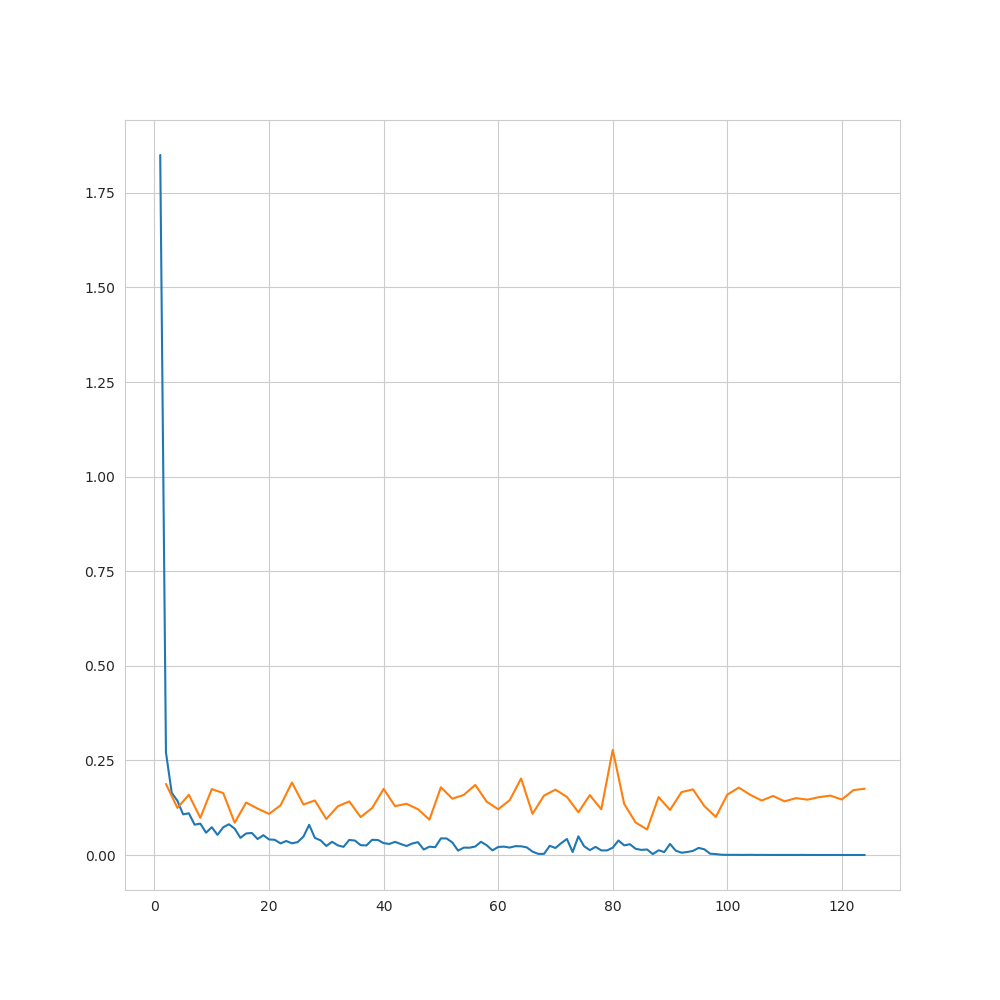
10. ディスカッション
学習に関して
- 想定通りに学習が進まなかった(=訓練データに対しては損失関数の減少が見られる一方、未知データに対しては、減少していない)
→過学習、構造を完全には捉えられていない - 今回使用したアーキテクチャにはある程度過学習を防ぐ仕組みが組み込まれている(dropout等)
→それにも関わらず想定通り学習が進まなかったことから、データ自体の性質(ランダム性など)の影響が大きいと考えられる
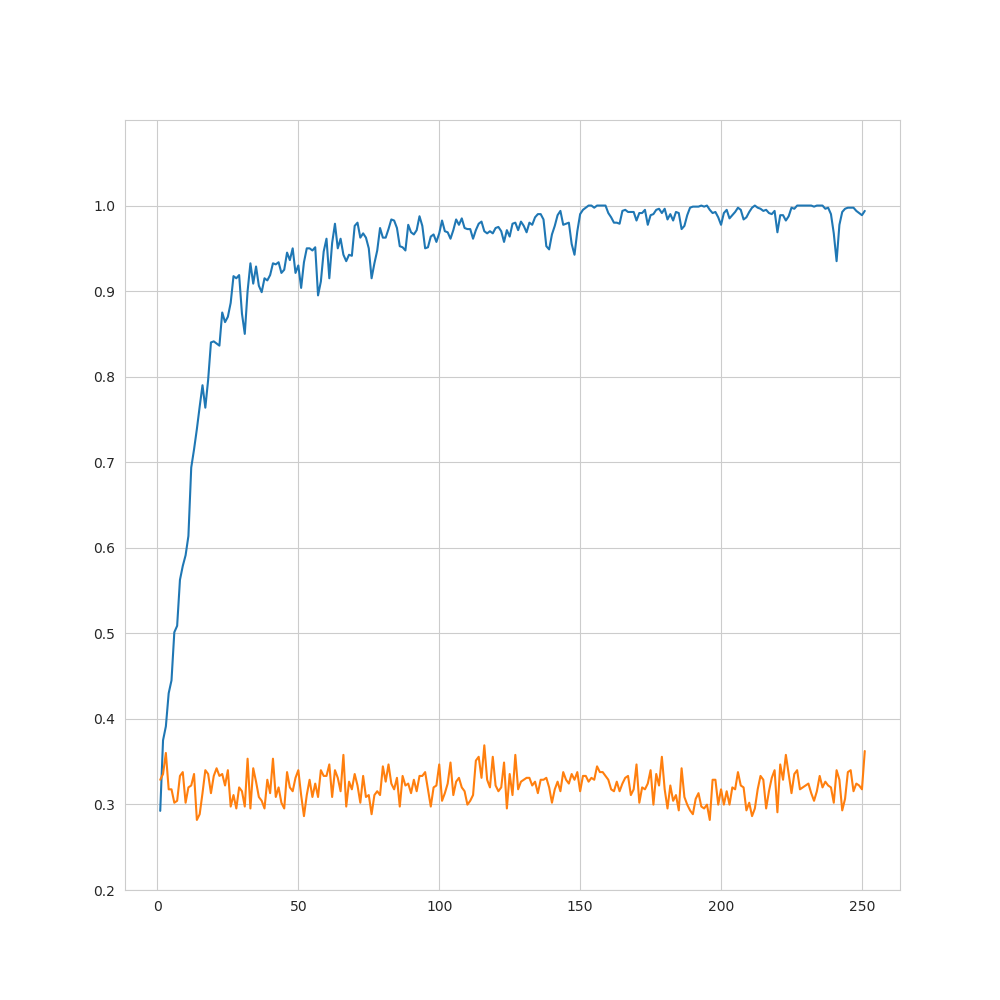
11. 参考 同じ学習器で別データ学習の時のグラフ
異常検知実装の際に同じ学習モデルを利用テストデータのLossも下がっており、学習が収束。実際の異常判別結果も97%の数値。はじめはバグを疑ったが別データでは学習出来ているので、単純なケアレスミスではないとみられる。
12. ディスカッション
売買シミュレーションに関して
最終的に黒字となったのはt-SNE/5pips (同じ5pipsでもPCAではどんどん負けている)
→偶然でないとすれば、PCA適用時に欠落した情報がt-SNEでは保持された可能性がある
なお、1pipsでも、2017年に入るまではPCA版とt-SNE版でかなり異なった結果となっている。
13. 今後の課題
- ローソク足チャートの代わりになるデータを探してこの研究を行ったが、動画から明らかな特徴は表れていなかった。
人間が見てわかるような物体にして学習させたい。
過学習の克服 - チャートのデータだけでなく、金利や株価、経済のファンダメンタルデータをインプットに加える
次元削減の問題
→最適な次元削減手法を検討あるいはそもそも多次元データをそのまま扱えるようなネットワークを試す ・t−SNEとPCAでパフォーマンスがかなり違う
14. 参考文献
[1] R.Fujimaki, S.Morinaga: Factorized Asymptotic Bayesian Inference for Mixture Modeling. Proceedings of the fifteenth international conference on Artificial Intelligence and Statistics(AISTATS),2012. [2] C.R.Qi, H.Su, K.Mo, and L.J.Guibas: Pointnet: Deep learning on point sets for 3d classification and segmentation, IEEE Conference on Computer Vision and Pattern Recognition,2017 [3] C.R.Qi, H.Su, and L.J.Guibas: Pointnet: PointNet++: Deep Hierarchical Feature Learning on Point Sets in Metric Space, Neural Information Processing Systems,2017 [4] 石原龍太: 多層ニューラルネットワークと GA を用い た TOPIX 運用 AI, 第19回 人工知能学会 金融情報学 研究会(SIG-FIN), 2017 [5] 今村光良, 中川慧, 吉田健一: 機械学習を用いた共和 分ペア・トレード戦略, 第19回 人工知能学会 金融情 報学研究会( SIG-FIN), 2017 [6] 梅田裕平, 金児純司,菊地英幸: トポロジカルデータア ナリシスと時系列データ解析への応用, FUJITSU, Vol. 69, No. 4, pp. 97-103, 2018
適時開示情報の業績に対するリスク有無の自動判定
1. はじめに
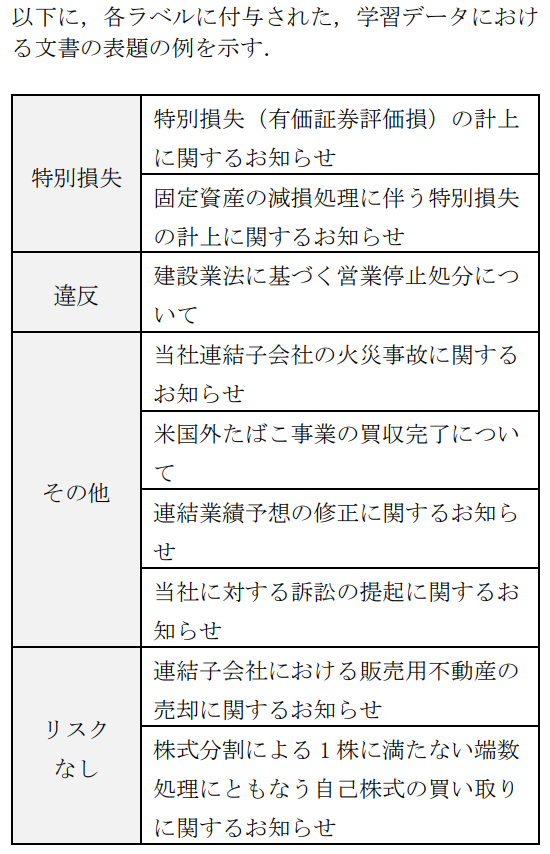
近年、個人投資家の数が増加している中、適時開示情報への関心が高まっている。適時開示情報とは上場企業が義務付けられている「重要な会社情報の開示」のことであり、適時開示情報の中には、その上場企業の株価に影響を与える可能性の情報もある。特に、例えば「業績予想の修正」や「営業停止処分」といった業績にリスクのある情報は株価への影響も大きく、投資判断にも大きな影響を与える。しかし、適時開示情報はインターネット上でいつでも閲覧できるが、常に新しい情報が掲載され続けているため、すべてを閲覧することは困難であり、さらに、その中から業績にリスクのある情報のみを判別して閲覧することは多大な労力を必要とする。そこで、本研究では、上場企業が公開する適時開示情報を、深層学習によって業績にリスクがあると考えられる情報のみを自動で抽出し、それらを分類する手法を提案する。例えば、「業績予想の修正に関するお知らせ」の適時開示情報を「リスクあり」と判定し、「特別損失」に分類する。 本研究により、業績にリスクのある適時開示情報の閲覧を容易にし、投資家の投資判断に役立てることを目的とする。関連研究として、例えば、企業の発行している「決算短信」をテキストマイニングの技術を用いて解析し、経済市場を分析する研究などが行われている[1][2][3][4][5]。 酒井らは企業の決算短信PDFから業績要因文を自動抽出する研究を行っている[1]が、業績要因のみでは、業績に対するリスクを判断することはできない。それに対して、本研究ではリスクの有無を判定できる点が異なる。
2. 提案手法
2-1 手法概要
Step1: 適時開示情報の中から業績にリスクがあると考えられる情報を人手で抽出して学習データとし、その学習データを後述のワードリスト(表1)に示す語により分類する
Step2: 学習データ・テストデータを適時開示情報の文書ごとにDoc2Vecによりベクトル化する
Step3: 深層学習におけるモデルの最適な中間層やbatchを決定する
Step4: Chainerを用いて学習データを用いて学習を行い、Chainerのモデルを作成する
Step5: 作成されたモデルに基づき、リスクがある文書をリスクあり、リスクなしに分類し、さらに、リスクありと判定された文書を、その内容に基づいて分類する。
2-2 使用するデータ
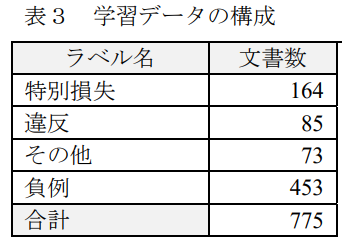
学習データには2017年の適時開示情報を使用し、テストデータには2016年の適時開示情報を使用する。 学習データの作成方法を以下に述べる。表1に示したワードリストにある語が含まれている文書を「リスクあり」とし、含まれていない単語を「リスクなし」とする。次に「リスクあり」とした文書の中から「特別損失」、「違反」、「その他」の3種類に分類する。「その他」には「火災」、「訴訟」、「損害」といった情報が含まれている。分類には表2に示されている語とラベル名に基づいて分類している。分類した学習データの構成を表4に示す。


2-3 深層学習に使用するモデル
Chainerによって学習データからモデルを作成する。中間層を決定する上で適したモデルを作成するために、次のような手順を考える。モデルには、「入力層 → X → X → X → 出力層」となる多層パーセプトロンを用いる。
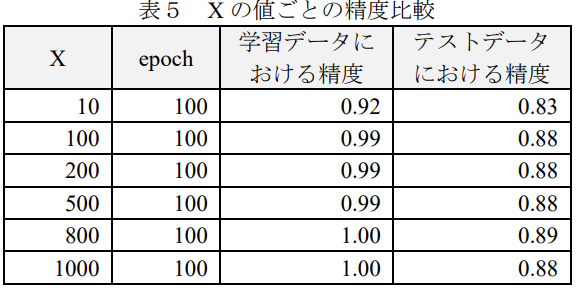
Step1: epochを30として中間層 X のユニット数を変化させて、テストデータにおける精度を比較する
Step2: 最適な中間層 X におけるユニット数を中間層に使用する
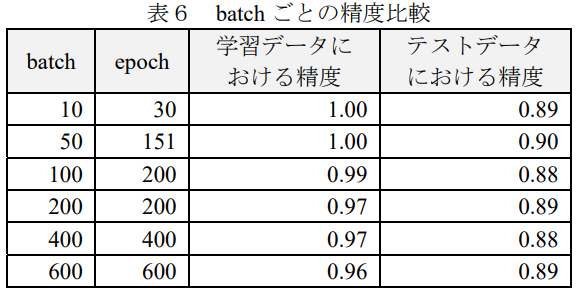
Step3: batchの値を変化させて、テストデータにおける精度を比較する
Step4: 最適なbatchの値を使用する
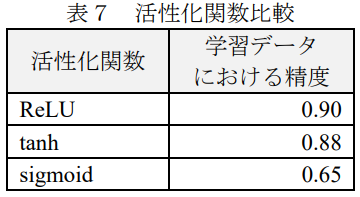
中間層 X のユニット数は、過学習を避けるため最も早く「学習データにおける精度」が1になった800を使用し、batchには同様の理由で50を使用することにした。入力層はDoc2VecによってWikipediaから約500MBの記事を次元数400 で学習させたモデルに基づき、学習データの文書をベクトル化したベクトルを使用する。学習データではなくWikipediaを使用した理由は、学習データのみでは Doc2Vecの学習に必要な十分なデータがなかったためである。出力層は(2.2)により分類ラベル数の4 とした。活性化関数には ReLU 関数を使用した。
3. 評価
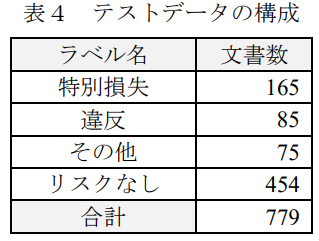
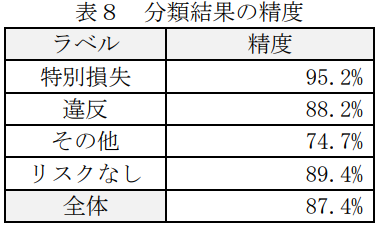
本手法の評価を行った。評価用の正解データは、テストデータとした2016年の適時開示情報から、表1で示したワードリストに基づき作成した。表4にテストデータの構成を示す。分類の評価結果を表8・表9に示す。分類の全体精度は 87.4%であった。
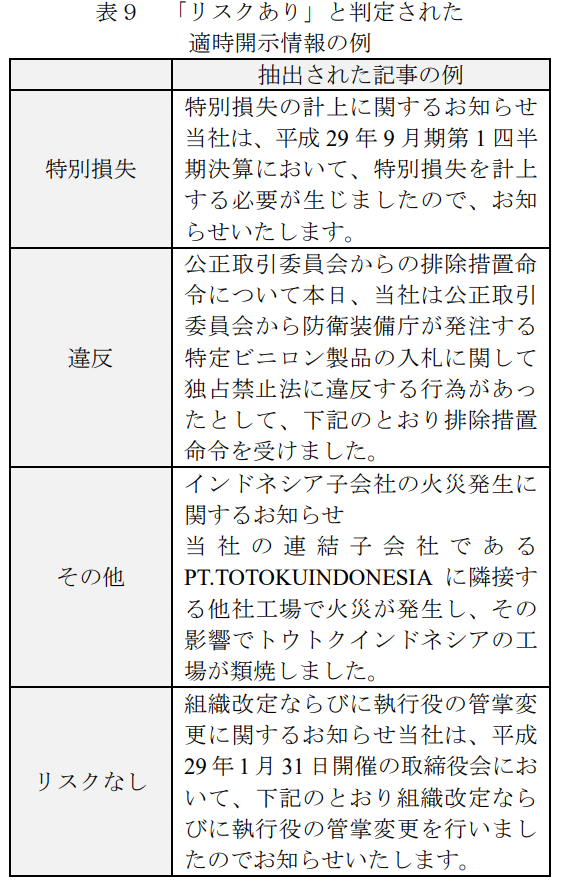
最も低い精度であったラベルは「その他」で 74.7%、最も高い精度であったラベルは「特別損失」で 95.2%であった。これは「特別損失」の文書の特徴は掴めているが、「その他」は特徴が掴みづらかったと言える。 以下に、本手法によって「リスクあり」と判定された適時開示情報の例を表9に示す。
4. 考察
表8より、各ラベルとも精度が80%を超えており、良好な精度を達成しているが、「その他」における精度が74.7%と低い結果となっている。これは「その他」には「火災」や「損害」に関する文書など様々な文書が含まれているため、区分の幅が広くなってしまったためであると考えられる。一方で、「リスクなし」の精度は89.4%と高い精度が得られており、「リスクあり」と「リスクなし」の分類は高い精度で分類できているということが言える。本手法により、ワードリストで設定した語が含まれていないにもかかわらず、正しく「リスクあり」と判定された例があった。以下に例を示す。
・「リスクあり」と判定した例
(略)損益の状況<連結決算の概況>平成29年3月期第 四半期決算総括1実質業務純益<1>は、連結子会社からの利益寄与が増加した一方、単体の資金関連利益の減少等により、前年同期比 205 億円減益(略)
—これは表1のワードリストに載っているワードは含まれていないが、類似する単語を抽出して分類できたものであると考えられる。
・「リスクなし」と判定した例
平成28年1月5日にノースカロライナ州ナッシュ郡ロッキーマウントのゲートウェイブルバード200に位置するホテルで発生した火災に関して、(略)今後の見通し本件和解金は損害保険により支払われるため、当社には財務上の負担はなく、平成30年3月期連結業績への影響はありません。
—これは「火災」という単語が含まれているが、負例と判定している。以上のようにワードリストの単語による抽出では得られないような文書を、「リスクあり」の文書の特徴を学習することによって正しく分類ができているということが分かった。
5. むすび
本研究では、深層学習によって適時開示情報を「特別損失」「違反」「その他」「リスクなし」の4種類に分類する手法を提案した。評価の結果として全体精度は 87.4%であったが、ワードリストの単語の有無に関わらずに文書の特徴を学習することができていたことが分かった。また本研究の分類器を実際の業務に適用することを考える際に、「リスクあり」である適時開示情報を「リスクなし」と判断してしまったり、「リスクなし」であるものを「リスクあり」と判断してしまうことは大きな問題である。そのためリスクの有無の分類が非常に重要な点であるが、本研究では「リスクなし」における精度が89.4%と高い精度を得ることができた。本研究では、適時開示情報からリスクの有無を自動判別する手法の提案であったが、実務への応用を考慮すると、判別されたリスクが当該企業以外に派生するリスクを同時に把握することが求められると考える。つまり、企業活動に重要な影響を与える内容を含んだ発表文書の内容に応じ、さらに当該発表企業と取引関係、資本関係、競業関係等、影響が及ぶと思われる関連先企業をその関係性を含め抽出することができれば実務への応用が期待できる。
参考文献
[1] 酒井浩之,西沢裕子,松並祥吾,坂地泰紀,“企業の決算短信 PDF からの業績要因の抽出”,人工知能学会論文誌, vol.30, no.1, pp.172-182, 2015.
[2] 坂地泰紀,酒井浩之,増山繁, “決算短信 PDF からの原因・結果表現の抽出”, 電子情報通信学会論文誌D, vol.J98-D, no.5, pp.811-822, 2015.
[3] Shiori Kitamori, Hiroyuki Sakai, Hiroki Sakaji,“Extraction of sentences concerning business performanceforecast and economic forecast from summaries of financial statements by deep learning”, IEEE Symposiumon Computational Intelligence for Financial Engineering& Economics (IEEE CIFEr’17), Hawaii, November, 2017.
[4] 酒井浩之, 松下和暉, “決算短信からの業績要因文の抽出”, 第 11 回テキストアナリティクス・シンポジウム, pp.87-91, 2017.
[5] Hiroki Sakaji, Risa Murono, Hiroyuki Sakai, Jason Bennett, Kiyoshi Izumi, “Discovery of Rare CausalKnowledge from Financial Statement Summaries”, IEEE Symposium on Computational Intelligence for FinancialEngineering & Economics (IEEE CIFEr’17), Hawaii,November, 2017.
[6] TDnet 適時開示情報閲覧サービス, 2018 アクセスhttps://www.release.tdnet.info/inbs/I_main_00.html
ここまでご愛読いただきありがとうございました!
よろしければ弊社SNSもご覧ください!
Twitter https://twitter.com/crystal_hal3
Facebook https://www.facebook.com/クリスタルメソッド株式会社-100971778872865/